At starte en automatiseringsproces fra EasyCatalog, kan virke som en uoverkommelig proces, men i dette blog indlæg, vil vi, hos Rezorz, give et par gode råd til en succesfuld implementering. Udgangspunktet for den bedste katalog automatisering med EasyCatalog er et god og struktureret datagrundlag.
Da EasyCatalog er datadrevet, har kvaliteten af datagrundlaget en meget direkte indflydelse på både det endelige produkt, og arbejdsprocessen.
Hvis en datakilde er ukomplet, eller har andre mangler, kan det stadig være brugbart. I dette tilfælde skal man være opmærksom på:
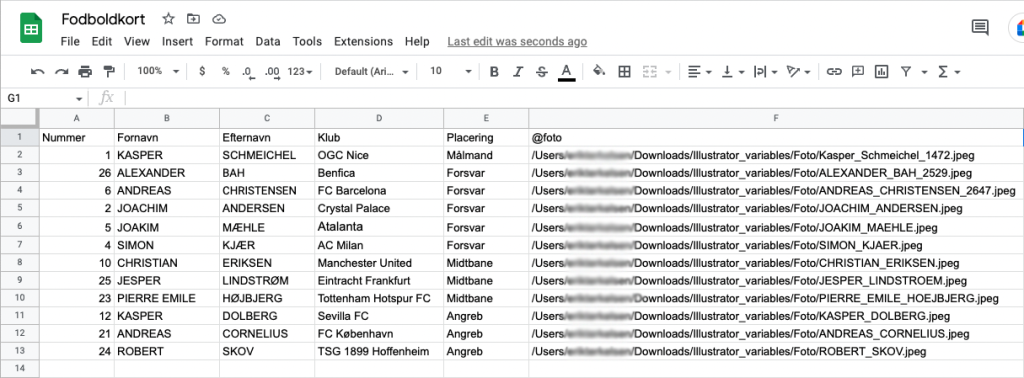
- Alt, hvad der ønskes vist på det trykte produkt, skal være tilgængeligt i datakilden.
- Refencer til billedfiler, som der skal anvendes i den paginerede version, skal være tilgængelige enten ved fulde stier, delvise stier, eller URL’er i datakilden.
- Hver post skal have en unik identifikator, der aldrig ændres, så længe datakilden er i brug. Typisk vil dette være en SKU eller produktkode, og det kræves, så der kan findes en sammenhæng, når datakilden bliver opdateret. Ligeledes skal hvert felt have et unikt navn.
Hvis der ønskes en bestemt struktur, såsom hovedvarer og undervarer, skal dette også være tilgængeligt i datakilden. Dette skal også fremgå af datakilden.
Nogle gange skal grupper af poster vises sammen på siden – dette kunne være i en tabel. EasyCatalog har mulighed for at gruppere poster sammen, og paginere dem automatisk i samme bibliotekselement.
Hvilke datakilder kan så anvendes?
EasyCatalog kan nemt integreres med din eksisterende datakilde, der er dermed ingen ny database opsætning påkrævet. Det er en fordel, når der allerede er brugt tid og penge på en centralisering af data.
EasyCatalog kan importere data fra:
- Delimited filer, så som CSV
- Microsfot Excel-regneark
- Google Sheets
- ODBC Databaser som MySQL, Orcale, Microsoft SQL Server, Filemaker mm.*
- Product Information Management (PIM) og Asset Management systemer som Elvis*
* Krav om tilkøbte moduler
En god opsætning, med struktureret data, kan derfor gøre det meget hurtigere at opsætte og vedligeholde flere sprogversioner og store samlinger af opsætninger.
Følg med på bloggen for flere gode fremgangsmåder, eller tag kontakt til os, for en snak omkring jeres næste projekt.